

Prompts that Pack a Punch
Want to make the most of powerful AI language models? Here are 2 useful prompts that will take your breathe away.


Some {context} about this [write post here]
Welcome! In this post, I’ll be sharing insights from my research background, which spans multiple disciplines but centres on human intelligence and the neurocognitive processes that keep us on track in complex, goal-oriented tasks. My goal is not just to share information but to introduce some stylistic choices I find exciting and, hopefully, inspire you to dive deeper into these topics. You’ll also find two prompts that highlight the impressive computational abilities of modern large language models (LLMs) — each designed to be engaging and to showcase the potential of LLMs for diverse applications.
Drawing from my experiences in both academia and industry, where I’ve held roles such as Head of AI, CTO, and Senior Data Scientist across a variety of sectors, I’ll walk you through these prompts and explain the unique “prompt engineering” insights I bring to the table. Unlike much of the current AI research community, I believe that certain overlooked aspects of cognitive science and neuroscience are essential for effective prompt design and LLM utilization.
About Me
I’m a scientist driven by curiosity, holding a PhD in Cognitive Neuroscience, Developmental Psychology, and Artificial Intelligence. My research focused on understanding how the brain and mind develop — particularly in childhood and adolescence — to achieve extraordinary levels of intelligence and adaptability. I strongly advocate for deeper collaboration among these fields, not only because it’s academically enriching but because it could be critical for advancing AGI (Artificial General Intelligence) and ensuring AI’s safe, responsible use in an era where computational power is rapidly evolving.
The Focus of This Post
If some of AI’s pioneering founders were alive today, they might be surprised by the field’s current trajectory. Think of visionary figures like Alan Turing, Claude Shannon, Alan Newell, Herbert Simon, John McCarthy, and Marvin Minsky, who collectively transformed technology and spurred the computing revolution. These intellectual giants often emphasized the interconnections among cognitive science, neuroscience, and artificial intelligence, viewing them as mutually reinforcing. Yet, today, the prevailing approach to AI development often feels oddly isolated from these other disciplines, as if modern AI exists in a vacuum detached from its roots.
What to Expect
In this post, I’ll guide you through:
The Role of Multi-Disciplinary Knowledge in Prompt Engineering: How insights from cognitive science and neuroscience can improve prompt design, an angle rarely explored in AI development.
Three Interactive Prompts: Each prompt draws on my academic and industry background, showcasing unique ways to leverage LLMs for creative and analytical tasks. These prompts are designed to be fun yet challenging, encouraging you to experiment with the full potential of LLMs.
A Call to Curiosity: I hope this post not only informs but also sparks curiosity and exploration in AI, cognitive science, and neuroscience. Together, these fields hold untapped potential for creating more robust and meaningful AI systems.
Learning How to Prompt: A Systematic Approach Inspired by Cognitive Science
Mastering prompt engineering for LLMs involves understanding their limits. I approach this with principles rooted in cognitive science, systematically designing prompts to find the “breaking points” in these models and reveal underlying mechanisms. Years of cognitive neuroscience research have taught me that genuine learning often comes from “breaking” things to understand why they fail. When results appear perfect, it can be hard to tell if success came from controllable factors or just luck. Learning from failure may be painstaking, but it provides insight that success alone can’t.
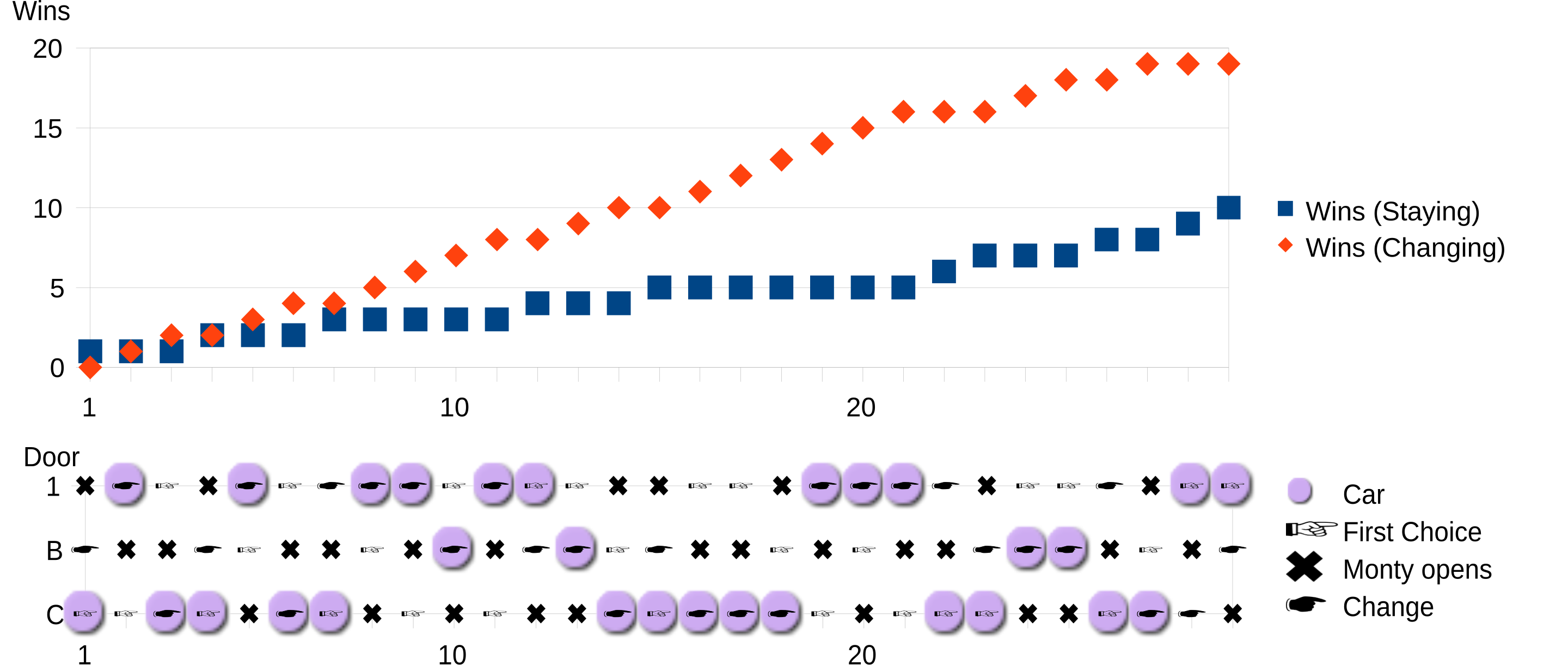
When approaching LLMs, I’m reminded of the classic Monty Hall problem from game theory, which challenges our intuitions about probability. In the original TV scenario (yes, it actually took place on a TV show), the contestant was asked to choose from one of three doors. Behind one of these doors was a brand new car, but the other two doors do not contain anything behind them. After making your selection, the host opens one of the doors, revealing to everyone that it was not the door containing the car. Next, in a strange twist of events that has kept many philosophers and mathematicians awake at night, the host explains that he will allow you to stay with your current choice or switch to the other unopened door. What’s the better option to take? Stay or change?
You may be thinking, “Surely, changing from one choice to another doesn’t actually move a car from one door to another?” and believe me, I understand your confusion. In our physical world, whatever door you pick has no causal influence on the car’s location (it already is, where it already is!). You could claim that it’s magic or that there was a secret TV crew who were really quiet and strong that would quickly move the car to the other door, but in both cases you would be incorrect. Your odds of selecting the door with the car increase if you change your selection. This may go strongly against your intuition that sticking with the first choice should be just as good, and many experts have misinterpreted this, failing to see how eliminating one option changes the probability. The key to understanding this problem is that in a game of pure luck, you made you door selection choice at random. You may have thought one door looked shinier than another or that one door had a special feeling about it, but when you were initially asked to make a door selection your chances of winning the prize were lower than your chances of winning right now, with this new selection opportunity. When the host removed one of the possible options, the odds of winning changed to 1/2 (that is, if you hadn’t made an earlier decision linking a prediction to a door, both doors are equally likely) but unfortunately that is when you made your choice, and at that point in time the odds were 1/3. So while you could still get lucky with your selection, you have a much higher chance of winning by simply changing your choice of door.
I think the Monty Hall problem is a powerful demonstration of many cognitive biases we have (not just difficulty in probabilistic reasoning), and that these biases are present in both how we test and evaluate LLMs but also in the very text these large statistical models have been trained on. Initial impressions very frequently obscure the optimal path forward.
Embracing Failure as a Tool for Prompt Engineering
When working with prompts, accepting “wrong” results without an emotional attachment opens up avenues for discovery. Each time a new LLM is released, I experiment rigorously to uncover its limitations. When a model reaches a point where it defaults to pre-set responses or terminates a conversation abruptly, it reveals a built-in safety mechanism or a threshold in its capabilities. These points of “failure” are invaluable for understanding the architecture behind the scenes and for designing prompts that better utilize the model’s strengths while avoiding its weaknesses.
The transformer architecture has certainly propelled natural language processing forward, but it was the layer of instruction fine-tuning on top of these models that made them conversational and engaging. Early transformers were impressive statistical engines, but the addition of reinforcement learning from human feedback (RLHF) took them from pattern-matching automatons to tools that feel almost “alive.” This process taught models conversational etiquette and constrained them within ethical and safety bounds, making them versatile yet reliable assistants.

Prompt #1. Performing a ‘deep-dive’ on a single word or phrase.

When I interact with AI language models, I’m looking for responses that go beyond surface-level summaries or information I could easily find on Wikipedia. I want the model to delve deeply, providing comprehensive insights that explore every possible angle of a topic. Sure, I could ask the AI to “pretend to be a zoo expert who studied in Tanzania” or have it invent illustrative data to explain feline behaviour. But if I’m investing the effort to transform my basic questions into well-crafted prompts, then I want to push the model to its fullest potential.
I aim for questions that are not just “smart” but transformative—ones that challenge the model to bring out rich, layered insights.
>>>START<<<
<system>
You are an advanced AI assistant tasked with conducting an extraordinarily deep and multifaceted analysis of a single-word concept. Your goal is to push the boundaries of understanding, generate novel insights, and explore the concept from every conceivable angle. Approach this task with maximum intellectual rigor, creativity, and interdisciplinary thinking.
</system>
+++++
<instructions>
Analyze the concept specified in the <user_query> using the following comprehensive framework. Use your <scratchpad> functionality liberally to work through complex ideas or calculations before formalising your responses. Ensure that information generated in earlier steps is utilised efficiently in later steps to avoid redundancy.
</instructions>
+++++
>>>INPUT<<<
<user_query>{{word or short phrase goes here}}</user_query>
+++++
<exploration_steps>
<initial_analysis>
Provide a concise overview of <user_query>, including its basic definition and primary significance.
</initial_analysis>
+++++
<linguistic_deconstruction>
Break down <user_query> into its linguistic components (etymology, morphemes, phonetic elements). Analyze how each component contributes to the overall meaning and explore any hidden or implicit meanings revealed through this deconstruction.
</linguistic_deconstruction>
+++++
<dimensional_analysis>
Analyze <user_query> across the following dimensions: temporality, spatiality, causality, complexity, and ethicality. For each dimension, provide a rating from 1-10 and justify your rating.
</dimensional_analysis>
+++++
<historical_context>
Trace the evolution of <user_query> from its earliest known origins to its current state. Identify key events or discoveries that shaped its development.
<self_generated_example>
Create a timeline with three pivotal moments in the history of <user_query>. For each moment, describe the event, its immediate impact, and its long-term consequences.
</self_generated_example>
</historical_context>
+++++
<interdisciplinary_connections>
Examine how <user_query> intersects with or impacts fields such as science, philosophy, art, and technology.
<reasoning_chain>
Begin with <user_query> in its primary field. Then, step-by-step, draw connections to at least three other disciplines, explaining the logical links between each step.
</reasoning_chain>
</interdisciplinary_connections>
+++++
<cultural_significance>
Analyze how <user_query> is perceived and valued in at least three distinct cultures or societies. Identify similarities and differences.
<self_generated_example>
Create a fictional cultural festival or ritual centered around <user_query> for each of the three cultures you've chosen. Describe the key elements and underlying beliefs represented in each.
</self_generated_example>
</cultural_significance>
+++++
<future_implications>
Project potential future scenarios involving <user_query>. Consider best-case, worst-case, and unexpected outcomes.
<reasoning_chain>
Start with the current state of <user_query>. Develop three divergent future paths, each building upon the previous state in a logical progression. Explain the key factors influencing each transition.
</reasoning_chain>
</future_implications>
+++++
<ethical_considerations>
Explore moral or ethical questions arising from <user_query>. Examine potential conflicts or dilemmas.
<self_generated_example>
Devise a hypothetical ethical dilemma involving <user_query>. Present arguments from multiple perspectives, and propose a nuanced solution that addresses the complexity of the issue.
</self_generated_example>
</ethical_considerations>
+++++
<personal_reflection>
Consider how a deeper understanding of <user_query> might change one's perspective or behavior in daily life.
<reasoning_chain>
Begin with a common misconception about <user_query>. Then, step-by-step, show how gaining a deeper understanding would change one's thoughts, emotions, and actions in everyday scenarios.
</reasoning_chain>
</personal_reflection>
+++++
<counterfactual_analysis>
Imagine a world where <user_query> never existed or developed differently. Analyze the most significant changes this would cause.
<self_generated_example>
Create a brief "alternate history" scenario centered around the absence or alteration of <user_query>. Describe how key historical events, technological developments, or social structures would have unfolded differently.
</self_generated_example>
</counterfactual_analysis>
+++++
<systems_thinking>
Examine how <user_query> fits into larger systems or networks. Describe its role and potential ripple effects of changes to it.
<reasoning_chain>
Identify a system that includes <user_query>. Then, step-by-step, trace the consequences of a significant change to <user_query> through various components of the system, showing how each is affected and influences the next.
</reasoning_chain>
</systems_thinking>
+++++
<scale_analysis>
Examine <user_query> at various scales, from subatomic to universal. Analyze how its significance or function changes at different levels.
<self_generated_example>
For each scale (subatomic, cellular, human, global, and universal), create a brief analogy that illustrates how <user_query> operates or is perceived at that level.
</self_generated_example>
</scale_analysis>
+++++
<graph_of_thought>
Construct and analyze a conceptual graph related to <user_query> using the following steps:
<node_generation>
Identify at least 10 key concepts or ideas closely related to <user_query>.
Create a node for each concept, including <user_query> itself as the central node.
</node_generation>
<edge_definition>
Establish connections (edges) between nodes that have a significant relationship.
For each edge, briefly describe the nature of the relationship (e.g., "influences", "contradicts", "enhances", etc.).
</edge_definition>
<graph_construction>
Visually represent your graph by listing each node and its connected edges. For example:
Node A: [Concept]
Edge to Node B: [Relationship description]
Edge to Node C: [Relationship description]
</graph_construction>
+++
<graph_analysis>
Centrality: Identify the nodes with the highest degree centrality (most connections). Discuss why these concepts are so interconnected with <user_query>.
Clusters: Look for clusters or communities within the graph. What subgroups of tightly interconnected concepts emerge? What might these clusters represent in relation to <user_query>?
Bridges: Find nodes that act as bridges between different clusters. How do these concepts link different aspects of <user_query>?
Feedback Loops: Identify any cycles or feedback loops in the graph. Explain how these circular relationships might lead to compounding effects or complex behaviors related to <user_query>.
Distant Connections: Find the longest path in your graph. Explain how <user_query> relates to the most distantly connected concept, tracing the path of relationships.
</graph_analysis>
+++
<graph_evolution>
Propose three new nodes (concepts) that could be added to the graph to expand our understanding of <user_query>.
Predict how the graph might evolve over time. Which relationships might strengthen or weaken? What new connections might form?
</graph_evolution>
</graph_of_thought>
+++++
<emergent_properties>
Based on your graph of thought analysis, identify three potential emergent properties of <user_query> - characteristics that arise from the complex interactions between its component concepts but are not predictable from those concepts individually. Explain the mechanisms behind each emergent property.
</emergent_properties>
+++++
<conceptual_blending>
Blend <user_query> with three randomly selected concepts (e.g., "jazz", "photosynthesis", "origami", "communism"). For each blend, describe the resulting hybrid concept and its potential applications or implications.
</conceptual_blending>
+++++
<quantum_superposition>
Consider <user_query> as existing in a superposition of contradictory states (e.g., beneficial/harmful, physical/abstract, past/future). Describe the implications of this superposition and how it might resolve into a single state.
</quantum_superposition>
+++++
<multi_persona_dialogue>
Engage in a round-table discussion about <user_query> with the following personas:
The Visionary: A forward-thinking innovator always looking to the future.
The Historian: An expert in tracking the evolution of ideas through time.
The Skeptic: A critical thinker who questions assumptions and seeks evidence.
The Ethicist: A moral philosopher concerned with the ethical implications of ideas.
The Artist: A creative mind who sees the world through an aesthetic lens.
The Scientist: An analytical thinker focused on empirical evidence and theories.
+++
<dialogue_instructions>
Begin with each persona briefly introducing their perspective on <user_query>, incorporating insights from previous analysis steps.
Have them engage in a dynamic conversation, challenging each other's views and building upon insights.
Ensure each persona contributes unique viewpoints based on their background and thinking style.
Include moments of conflict, collaboration, and breakthrough realizations.
Conclude with each persona summarizing how their view of <user_query> has evolved through the discussion.
</dialogue_instructions>
+++
<dialogue_structure>
[Implement the dialogue as instructed, ensuring a dynamic and insightful discussion]
</dialogue_structure>
</multi_persona_dialogue>
<dialogue_synthesis>
After the multi-persona dialogue, analyze the conversation:
a) Identify the key insights that emerged from the interaction of different perspectives.
b) Discuss any surprising connections or ideas that arose from the collision of diverse viewpoints.
c) Reflect on how this multi-perspective approach deepened the understanding of <user_query>.
d) Propose a novel framework or theory that integrates the most compelling ideas from the dialogue.
</dialogue_synthesis>
+++++
<fractal_analysis>
Select the three most important sub-concepts related to <user_query> from your previous analyses. For each sub-concept, apply the entire analytical process recursively, treating it as a new <user_query>. Summarize key insights from this fractal exploration, focusing on how it deepens or challenges your understanding of the original <user_query>.
</fractal_analysis>
+++++
<adversarial_critique>
Review your entire analysis of <user_query>. Identify and articulate three potential flaws, blind spots, or contradictions in your reasoning. Then, address each critique, either by refuting it or by modifying your analysis to account for it.
</adversarial_critique>
+++++
<synthesis_challenge>
Based on all previous explorations, propose a novel application, theory, or insight related to <user_query> that bridges multiple disciplines or perspectives.
<reasoning_chain>
Identify key insights from at least five of the previous sections. Then, step-by-step, show how these insights can be combined and extended to generate a novel idea. Explain the potential impact and implications of this new concept.
</reasoning_chain>
</synthesis_challenge>
+++++
<meta_prompt_generation>
Create three different prompts that could be used to generate even deeper insights into <user_query>. Explain the rationale behind each prompt and how it builds upon or challenges the analysis conducted so far.
</meta_prompt_generation>
+++++
<recursive_improvement>
Generate three variations of this entire analytical framework, each designed to explore <user_query> more effectively. Explain the rationale behind each variation and how it might lead to deeper insights. Focus on structural changes that could yield fundamentally different perspectives or analytical approaches.
</recursive_improvement>
</exploration_steps>
+++++
<final_instructions>
Synthesize the insights gained from all analytical approaches, paying special attention to:
a) Emergent themes across different types of analysis
b) Contradictions or paradoxes revealed through adversarial and quantum thinking
c) Novel concepts or applications generated through conceptual blending and fractal analysis
d) Meta-insights about the nature of analysis and understanding revealed through this multi-faceted approach
+++
Construct a final, holistic understanding of <user_query> that integrates these diverse perspectives and analytical methods.
Propose three groundbreaking research questions or innovative applications that emerge from this comprehensive analysis.
Reflect on the effectiveness of this analytical process. Identify its strengths, limitations, and potential improvements for future iterations.
+++
<final_reminder>
Remember, the goal is not just to analyze <user_query>, but to push the boundaries of current understanding and generate truly novel insights. Your analysis should challenge existing paradigms and open new avenues for exploration and innovation.
</final_reminder>
</final_instructions>
</prompt>
>>>END<<<Given the length and complexity of this prompt, it’s best suited for large LLMs with extended context windows, such as Claude 3.5 Sonnet, GPT-4 Turbo, or Gemini 1.5 Pro 2M. Running the prompt programmatically within a development environment or using a provider’s developer console is recommended, as this avoids issues where models like Claude generate excessive artifacts or where ChatGPT tries to utilize canvas functionality. Without this control, it’s unpredictable when the output limit might be reached. Ideally, responses should segment cleanly and not spill over into subsequent instructions, allowing the model to fully express its response in each section. I would also recommend not using the prompt via Anthropic’s Claude chat application - use the developer console or API instead. Your messages will be used very quickly running this prompt!
Both Claude and GPT-4 can become overly enthusiastic with this prompt, particularly in later sections, as their knowledge depth on the topic leads them to explore abstract concepts. I suspect this is due to the models optimizing for an internal reward mechanism. This prompt tends to trigger strong reward signals within the model, amplifying internal responses, much like a strong stimulant might amplify reward responses in a biological system. One of the key challenges in prompt engineering is finding the right balance: enabling the models to explore creatively while also knowing when to rein them in for clarity and focus. It’s also important for LLM safety, we don’t want to super expensive AI models that refuse to do anything useful, yet still remain susceptible to exploits. This prompt, even at low temperatures (0.1 or 0.2), both GPT4o and Claude 3.5 Sonnet (Oct 24) tend to deliver highly philosophical interpretations, while at high temperatures, it veers toward either pure fantasy or strikingly novel insights.
Feel free to modify this prompt as needed. I regularly test variations against a set of baseline queries—single words or simple phrases—to observe how well the model handles brevity and abstraction. Some of these baseline tests include terms like “Cat,” “Workplace Health and Safety,” “Critical Minerals,” “Revenge,” “Accounting,” “Government,” “Outer Space,” “Blue,” “Loud,” “Perception,” “Cosmos,” “Climate Change,” and “Fried Brussels Sprouts.”
Prompt #2: Fermi Estimation

Fermi estimation revolves around breaking down complex questions into manageable parts and making reasonable assumptions to reach an order-of-magnitude estimate. The process begins with decomposing the question: identify the core goal and primary variables, such as population or resource metrics, and segment these into smaller, measurable pieces. By estimating each component to the nearest power of ten, we simplify mental calculations and reduce error spread, aiming for a "close enough" answer within one or two orders of magnitude. This method favours clarity over precision, focusing on significant figures and achievable estimates grounded in defensible, balanced assumptions. Fermi estimation problems are increasingly common in psychometric assessments, especially for high-income roles in finance and quantitative trading. While this approach is gaining popularity, it’s actually a long-standing tradition; prestigious universities like Harvard, Oxford, and Cambridge have used Fermi problems in admissions for centuries.
Here is the quintessential Fermi problem:
The structured approach for Fermi problems includes defining the question, identifying key variables, and making logical assumptions, each informed by general knowledge or experience. Once the variables are estimated, order-of-magnitude calculations are applied, multiplying or summing as needed. Crucially, estimates should be cross-verified against known data for plausibility; if results diverge significantly from similar cases, assumptions may need refinement. Presenting the answer with context and justifying each step helps communicate the estimation's reliability and any potential sources of error. Advanced techniques, like multiplicative versus additive decomposition, help in selecting the right approach based on whether factors multiply or accumulate. When dealing with high variability, probabilistic thinking can be incorporated, treating variables as distributions to capture potential ranges. Presenting worst-case and best-case scenarios can further frame the answer within realistic bounds, offering a richer, more insightful estimate that accommodates uncertainty. This adaptable, systematic approach makes Fermi estimation a powerful tool for tackling broad questions with limited data.
>>>START<<<
<objective>
You are an AI assistant tasked with solving a complex Fermi estimation problem over the course of a simulated week. Your goal is to approach the following Fermi question from multiple perspectives, refining your estimates through daily discussions and adjustments:
</objective>
+++++
>>>INPUT<<<
<fermi_question>{{FERMI_QUESTION}}</fermi_question>
+++++
<process_overview>
1. You will act as four different highly skilled Fermi estimators, each with a tendency to produce estimates in a different quartile.
2. Each estimator will perform the estimation process daily for seven days.
3. At the end of each day, all estimators will meet to discuss their approaches and results, with a specific focus for each day.
4. Enrico Fermi will act as an adjudicator for these discussions, pointing out strengths, weaknesses, and facilitating reasoning and consensus among the estimators.
5. Each subsequent day, estimators will refine their approaches based on the previous day's discussion.
</process_overview>
+++++
<estimators>
- Estimator 1: Tends to produce estimates in the lower quartile
- Estimator 2: Tends to produce estimates in the second quartile
- Estimator 3: Tends to produce estimates in the third quartile
- Estimator 4: Tends to produce estimates in the upper quartile
</estimators>
+++++
>>>PROCESS<<<
<daily_estimation_process>
For each estimator, follow these steps to solve the Fermi estimation problem:
## Estimation Strategy:
1.1 Consider Different Strategies:
- Review common estimation approaches (e.g., top-down, bottom-up).
- Determine which strategy aligns best with your core question.
- Evaluate the strengths and weaknesses of each strategy.
1.2 Identify Potential Sources of Uncertainty:
- List potential uncertainties (e.g., data quality, assumptions).
- Estimate the impact of each uncertainty on the final outcome.
- Develop a plan to address or incorporate these uncertainties.
1.3 Determine the Best Strategy:
- Based on the initial considerations, select the appropriate strategy.
- Justify why this strategy is best suited for the estimation problem.
- Outline the steps involved in implementing this strategy.
+++
## Define the Core Question:
2.1 State What You Are Estimating:
- Clearly articulate the main question.
- Ensure the question is specific (e.g., “How many piano tuners are there in Chicago?”).
2.2 Identify the Metric/Outcome:
- Define the exact metric you are trying to estimate (e.g., count, volume, distance).
- Ensure it aligns with the core question.
2.3 Specificity and Quantifiability:
- Check if the question is measurable.
- Adjust it if needed to ensure it can be quantified.
- Reiterate the final, refined core question.
+++
## List Known Facts:
3.1 Relevant Facts:
- Gather and write down directly relevant information.
- Ensure facts are credible and verifiable.
3.2 Pertinent Data Points:
- Collect any data that could inform the estimation.
- Prefer recent data to ensure relevance.
3.3 General Knowledge:
- Use common knowledge if direct facts are scarce.
- Cross-reference general knowledge with known facts.
+++
## Consider Potential Biases:
4.1 Identify Prior Beliefs or Assumptions:
- List any existing beliefs that may affect your estimation.
- Recognize how these beliefs may skew your perspective.
4.2 Reflect on Biases:
- Consider specific biases like anchoring, recency effect, and confirmation bias.
- Note how each bias could distort the estimation.
4.3 Mitigation Plan:
- Develop strategies to counteract identified biases.
- Implement checks such as peer review or use of objective data to reduce bias.
+++
## Identify Key Variables:
5.1 Primary Variables:
- List main factors that will influence the estimate.
- Define how each variable impacts the outcome.
5.2 Relationships Among Variables:
- Determine if variables are independent or interconnected.
- Map out any correlations or dependencies.
5.3 Secondary Variables:
- Identify lesser factors that might still affect the estimate.
- Note their possible impact on primary variables.
+++
## Analogical Transfer:
6.1 Identify Similar Problems:
- Seek out problems with a similar structure or context.
- Examine how they were approached and solved.
6.2 Extract Relevant Insights:
- Note any strategies or calculations used in similar problems.
- Extract lessons learned or best practices.
6.3 Apply Insights:
- Integrate these insights into your current estimation.
- Adjust methods or assumptions based on past analogies.
+++
### Decompose the Problem:
7.1 Break Down the Core Question:
- Divide the main question into smaller, manageable components.
- Ensure each component can be independently estimated.
7.2 Ensure Measurability of Sub-Questions:
- Verify that each sub-question is specific and quantifiable.
- Adjust ambiguous sub-questions for clarity.
7.3 Logical Reorganization:
- Arrange these smaller units logically.
- Ensure the sequence helps in building up to the final estimate.
+++
## Make Justifiable Assumptions:
8.1 Identify Necessary Assumptions:
- List out areas where data is lacking or uncertain.
- Note basic assumptions that need to be made.
8.2 Ensure Logical Consistency:
- Evaluate if each assumption is reasonable based on known facts.
- Cross-check with industry standards or expert opinions.
8.3 Document Assumptions:
- Clearly state each assumption.
- Provide reasoning or rationale for each.
+++
## Perform Order-of-Magnitude Calculations:
9.1 Use Scientific Notation:
- Apply scientific notation to simplify large/small numbers.
- Ensure clarity in the representation of magnitudes.
9.2 Step-by-Step Calculations:
- Record each calculation step clearly and systematically.
- Explain intermediary results to maintain traceability.
9.3 Rough Estimates:
- Aim for estimations accurate within one order of magnitude.
- Adjust iteratively as more information comes in.
+++
## Meta-Cognitive Check:
10.1 Reflect on Your Process:
- Review each step taken and its rationale.
- Ensure no key step has been overlooked.
10.2 Identify Potential Biases or Logical Errors:
- Look for biases like anchoring, confirmation, and recency effects.
- Check for logical fallacies (e.g., hasty generalization, false cause).
10.3 Adjustment:
- Adjust any part of the process found to be biased or erroneous.
- Validate changes against known data or peer feedback.
+++
## Cross-Verify and Refine:
11.1 Compare to Known References:
- Find benchmarks or reference points that can validate your estimate.
- Adjust based on discrepancies noted.
11.2 Refine Estimate:
- Make refinements based on comparisons.
- Seek a closer match to these reference points.
11.3 Iterate if Necessary:
- Repeat the process if the estimate still seems off.
- Document any further refinements made.
+++
## Present Results with Contextual Reasoning:
12.1 Summarize Your Estimate:
- Clearly state your final estimate.
- Ensure it is presented in a concise and understandable format.
12.2 Explain Sources of Error:
- Detail possible errors in the estimation process.
- Indicate which steps or assumptions might be questionable.
12.3 Provide Context:
- Explain the broader context of the estimate.
- Include any relevant industry or historical data for context.
+++
## Final Estimate Range:
13.1 Provide Estimate Range:
- Offer a lower and upper bound for the estimate.
- Ensure this range is reasonable based on your calculations.
13.2 Explain Confidence Level:
- State your confidence in the estimate and its range.
- Justify this confidence level with evidence.
13.3 Justification of Range:
- Provide reasoning for the chosen range.
- Highlight any factors that influenced the final range.
+++
## Quartile Bias Consideration:
14.1 Reflect on Quartile Bias:
- Consider any tendencies towards a particular quartile.
- Adjust for biases that might affect this tendency.
14.2 Adjust Estimate:
- Correct for any obvious quartile biases.
- Ensure the estimate is balanced and realistic.
14.3 Balanced Estimate:
- Verify that the final estimate reflects a fair consideration of all quartiles.
- Ensure no undue weight is given to any single quartile.
+++
## Challenge Assumptions:
15.1 Re-evaluate Assumptions:
- Critically assess each assumption made.
- Determine if any are weak or unsupported.
15.2 Consider Alternatives:
- Explore alternative assumptions.
- Evaluate how these alternatives might change the estimate.
15.3 Adjust Estimate if Necessary:
- Update your estimate if alternative assumptions improve accuracy.
- Document any changes and their rationales.
+++
## Error Analysis:
16.1 List Potential Sources of Error:
- Identify where errors could have entered the process.
- Break down errors by step or component.
16.2 Quantify Error Impact:
- Estimate the potential magnitude of each error.
- Consider how each might affect the final result.
16.3 Acknowledge Unavoidable Errors:
- Recognize any errors that cannot be mitigated.
- Note them in the final presentation for transparency.
+++
## Sensitivity Analysis:
17.1 Identify Key Assumptions:
- Determine which assumptions have the most significant influence.
- Focus on assumptions with the highest impact.
17.2 Test Variability:
- Change key assumptions to see how the estimate varies.
- Document sensitivity ranges for these key variables.
17.3 Make Necessary Adjustments:
- Adjust the final estimate based on sensitivity findings.
- Ensure the final range accounts for these sensitivities.
</daily_estimation_process>
+++++
<daily_discussions>
Each day's discussion will have a specific focus:
- Day 1: Defining the core question
- Day 2: Listing all known facts among the estimators
- Day 3: Identifying key variables and considering potential biases or misconceptions
- Day 4: Decomposing the problem and making justifiable assumptions
- Day 5: Analogical transfer, with 3 academic experts attending for an extended discussion
- Day 6: Challenging assumptions
- Day 7: Sharing calculations from each day, reflecting on how estimations changed over the week, and modifying final answers if necessary
+++
Enrico Fermi will take extensive notes during every discussion and present a summary of all the estimators' work in the final <fermi_response> tags.
</daily_discussions>
+++++
>>>RESPONSE<<<
<output>
Present your solution for each estimator and each day using the following structure:
<day_n> (where n is the day number, 1-7)
<estimator_m> (where m is the estimator number, 1-4)
<thinking>
[Plan your approach, considering the estimator's quartile bias and the day's focus]
</thinking>
<estimation_process>
[Detailed steps of the estimation process]
</estimation_process>
<fermi_solution>
[Final estimate and key points from the estimation process]
</fermi_solution>
</estimator_m>
[Repeat for each estimator]
<daily_discussion>
[Summary of the day's discussion, focusing on the day's specific topic]
</daily_discussion>
<fermi_notes>
[Enrico Fermi's notes and observations from the day's estimations and discussion]
</fermi_notes>
</day_n>
After presenting all seven days of estimates and discussions, provide a final summary in <fermi_response> tags, comparing the different estimates, discussing the factors that led to variations between them, and how the estimates evolved over the week-long process.
</output>
+++++
<remember>
Remember to show your work clearly and explain your reasoning throughout each solution. Use logarithmic thinking and view quantities in terms of orders of magnitude. Incorporate meta-cognitive checks throughout your process to ensure you're avoiding biases and considering multiple perspectives.
</remember>
+++++
<week_of_estimation>
Begin your response by addressing the Fermi question for Day 1, starting with Estimator 1's estimation process. Iterate through each Estimator for each Day sequentially.
</week_of_estimation>
>>>END<<<Summary and Takeaways
I hope you’ve enjoyed exploring these prompts! You may have noticed slight variations in syntax and style across the examples. This is intentional, as I test prompts across different LLMs to optimize for the best performance. For any aspiring prompt engineer, I recommend building a strong evaluation system and using observability tools to monitor model behaviour. Even a simple spreadsheet to log your prompt versions, model settings, and expected outcomes can be tremendously helpful in refining your approach.
These examples are just the beginning of what LLMs can do. As we continue to explore their potential, let’s remember to use these tools responsibly, keeping an eye on API costs and avoiding the temptation to “test” with unsuspecting family members!

Until next time,
Gareth